Nagios-Connector
Einführung
Neben dem Client Management ist das Monitoring der IT-Infrastruktur eine der Kernfunktionen in der heutigen IT. opsi ist ein Client-Management Werkzeug. Für das Monitoring gibt es erprobte und bekannte Opensource Lösungen. Daher der Ansatz, opsi nicht um ein Monitoring zu erweitern, sondern eine Schnittstelle zu bestehenden Lösungen anzubieten. Mit dieser Erweiterung von opsi wird eine Schnittstelle für die bekannte Monitoring Lösung Nagios zur Verfügung gestellt. In den folgenden Kapiteln wird der opsi-Nagios-Connector erläutert und Beispielkonfigurationen vorgestellt.
Der opsi-Nagios-Connector ist nicht fest an eine Monitoringsoftware gebunden. Programmiert wurde die Schnittstelle für Nagios/Icinga. Der Einsatz mit anderen Monitoringlösungen ist denkbar, wird momentan aber weder getestet noch unterstützt.
Die folgende Dokumentation beschreibt, wie der opsi-Nagios-Connector aufgebaut ist und wie man ihn konfigurieren muss. Es wird vorausgesetzt, dass eine funktionierende Installation von Nagios bzw. Icinga vorliegt.
Voraussetzungen
Voraussetzungen bei opsi-Server und -Client
| Dieses Modul ist momentan eine kostenpflichtige Erweiterung. Das heißt, dass Sie eine Freischaltdatei benötigen. Sie erhalten diese, nachdem Sie die Erweiterung gekauft haben. Zu Evaluierungszwecken stellen wir Ihnen kostenlos eine zeitlich befristete Freischaltung zur Verfügung. Bitte kontaktieren Sie uns dazu per E-Mail. |
Voraussetzungen beim Nagios-Server
Vorrausgesetzt wird eine Nagios Installation in einer aktuellen 3.x Version oder eine Icinga Installation mindestens in der Version 1.6. Der opsi-Nagios-Connector sollte auch mit allen Nagios-Kompatiblen Monitoring-Lösungen benutzbar sein, getestet wird diese opsi Erweiterung allerdings nur gegen Nagios und Icinga.
Für weitere Informationen siehe auch:
Konzept
Der opsi-Nagios-Connector besteht hauptsächlich aus zwei verschiedenen Komponenten. Im Folgenden werden beide Komponenten erläutert.
opsi-Webservice Erweiterung
Eines der Hauptschwerpunkte des opsi-Nagios-Connectors ist eine Erweiterung des opsi-Webservice. Die Webserviceschnittstelle bietet damit die Möglichkeit, Checks vom opsi-Server anzufordern. Das bedeutet, der Nagios Server verwendet die erweiterten Webservicemethoden zum Auslösen und Abfragen von Checks. Der Vorteil dieser Lösung ist, dass die eigentliche Checkausführung im opsi-System ausgeführt wird und somit der Aufwand auf den überwachten Systemen gering bleibt.
Diese Erweiterung stellt eine Sammlung von Checks zur Verfügung, die in einem späteren Kapitel einzeln vorgestellt werden. Hauptsächlich wurden opsi spezifische Checks eingebaut. "Normale" Systemchecks werden nicht über den opsi-Nagios-Connector angeboten und müssen auf konventionelle Weise ausgeführt werden.
opsi-client-agent Erweiterung
Ein weiterer Teil des opsi-Nagios-Connectors ist eine Erweiterung des opsi-client-agent. Da in einer opsi-Umgebung jeder Managed-Client einen laufenden opsi-client-agent hat, bietet es sich an, diesen als Nagios-Agent zu benutzen. Wichtig bei dieser Erweiterung ist zu wissen, dass nicht alle Funktionen eines Nagios-Agenten, wie z.B. NSClient++ implementiert wurden.
Die Möglichkeiten des opsi-client-agent umfassen das Ausführen von Pluginbefehlen auf der Kommandozeile und das Zurückliefern der Ergebnisse.
Für Situationen in denen erweiterte Funktionen vom Nagios-Agent wie NSCA benötigt werden, wird ein opsi-Paket für die Verteilung und Pflege des NSClient++ per opsi bereitgestellt.
Der Vorteil der Verwendung des opsi-client-agent ist zum Einen, dass kein zusätzlicher Agent benötigt wird und das der Monitoring-Server keine Zugangsdaten vom Client haben muss, da die Checks zum Client alle über den opsiconfd laufen. Dies vereinfacht auch die Konfiguration auf der Monitoring Seite um Einiges.
opsi-Checks
Im folgenden Kapitel werden Zweck und Konfiguration der einzelnen opsi-Checks erklärt.
Hintergrund zum richtigen Verteilen der Checks
In der allgemeinen Monitoring Sprache wird zwischen aktiven und passiven Checks unterschieden. Die Bedeutung besagt, ob Nagios/Icinga die Checks selber auslöst und ausführt (aktiv) oder ob die Hosts die Checks eigenständig ausführen und die Ergebnisse an Nagios/Icinga selbstständig zurückmelden (passiv).
Auch bei der opsi-Nagios-Connector Erweiterung gibt es diese zwei Unterscheidungen. Allerdings werden diese bei opsi als direkte- bzw. indirekte-Checks bezeichnet:
-
Direkt: Diese Checks werden auf dem Client ausgeführt und liefern Ergebnisse vom Client an den Monitoring Server.
-
Indirekt: Die Erhebung der Daten, die für diese Art von Checks relevant sind, findet auf Basis von Backend-Daten im opsi-System statt. Diese können von realen Situationen und Zuständen abweichen.
Ein gutes Beispiel für einen indirekten Check ist check-opsi-client-status. Dieser Check bezieht sich eigentlich auf einen Client, ausgeführt wird er aber auf dem opsi-Backend. Der Client-Status ist in diesem Fall der Zustand des Clients aus Sicht von opsi. Im Gegensatz dazu wird jeder Check der tatsächlich am Client ausgeführt wird als direkter Check bezeichnet.
Die richtige Verteilung der Checks und damit die richtige Konfiguration erfordert zunächst die Analyse der eigenen opsi-Umgebung. Da opsi sehr flexibel einsetzbar ist, können verschiedene Szenarien auftreten. Hier werden die am häufigsten mit opsi eingesetzten Installationsvarianten abgehandelt. (Für spezielle Installation sollten Sie uns kontaktieren oder direkt über einen bestehenden Supportvertrag Ihre Situation schildern.)
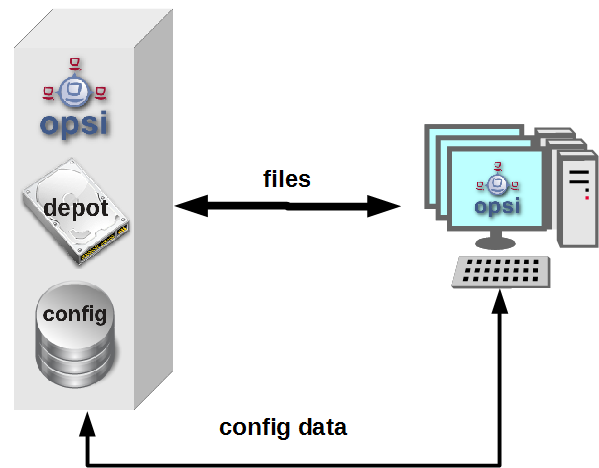
Ein opsi-Server (Standalone Installation): Diese Variante ist die am häufigsten eingesetzten Variante. Bei dieser Installation ist der Configserver auch gleichzeitig der Depotserver und somit werden alle Checks über den opsi-Configserver aufgerufen.
Mehrere opsi-Server mit einer zentralen Administration (Multi-Depot Umgebung): Um bei dieser Art der Installation die Checks richtig zu verteilen, muss man als erstes Verstehen, wie eine Multi-Depot Umgebung aufgebaut ist:
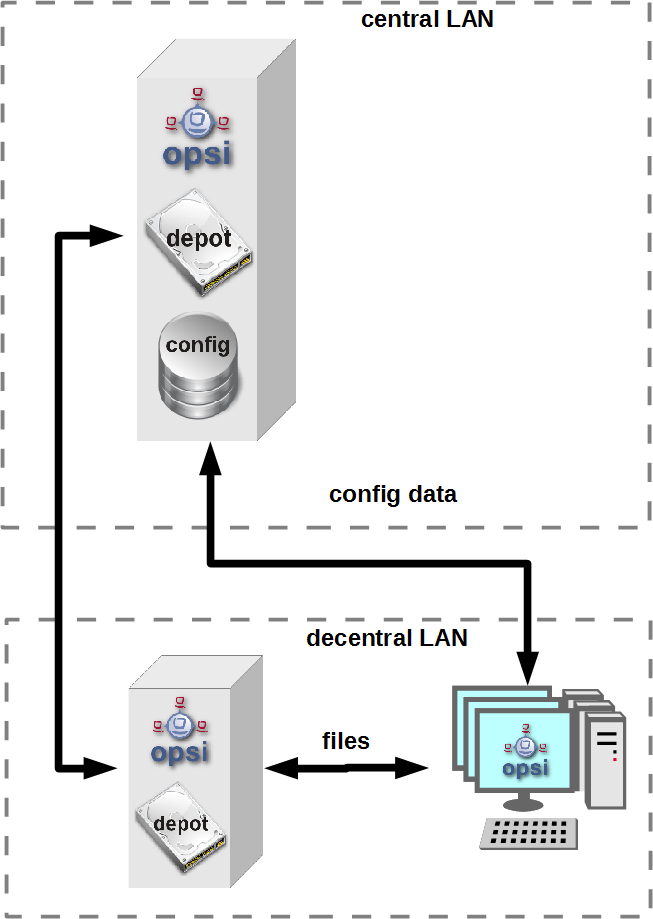
Wie im Bild zu erkennen, gibt es nur ein Daten-Backend, welches am opsi-Configserver angesiedelt ist. Jeder Check, der gegen das Backend ausgeführt wird, muss somit zwangsläufig über den opsi-Configserver. Somit werden alle Checks, die an die Depotserver gehen, intern an den Configserver weitergeleitet. Deshalb ist es sinnvoller diese Checks direkt gegen den opsi-Configserver auszuführen. Eine Ausnahme können die aktiven Checks gegen den opsi-client-agent bilden. Wenn zum Beispiel zwischen den Servern eine Firewall aufgestellt ist, die nur den Port 4447 durchlässt, können Clients an der Außenstelle eventuell nicht erreicht werden (Standardport 4441). In solchen Fällen kann es nützlich sein den aktiven Check am Depotserver in der Außenstelle auszuführen.
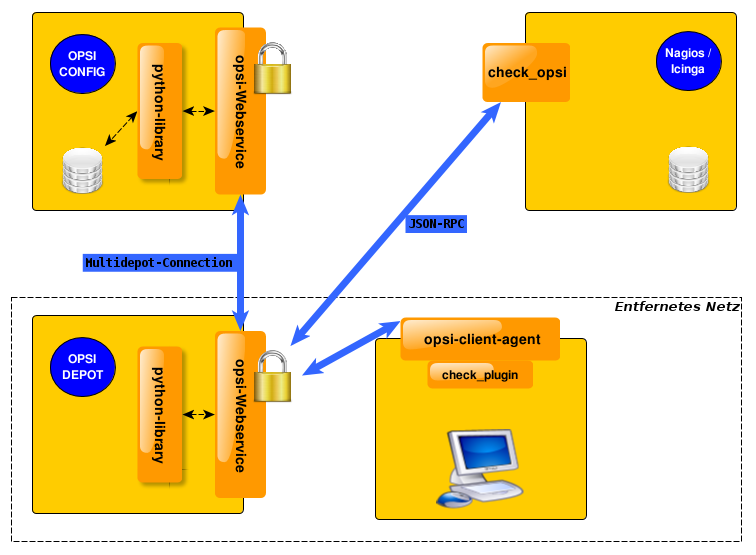
opsi-check-plugin
Auf dem Nagios Server gibt es nur ein opsi-check-plugin, welches aber eine große Zahl von Checks unterstützt. Deshalb hat dieses Plugin auch ziemlich viele Optionen. Eine Auflistung dieser Optionen wäre der Erläuterung nicht dienlich, deshalb wird an dieser Stelle darauf verzichtet. Die einzelnen Optionen, die benötigt werden oder möglich sind, werden bei den einzelnen Checks erläutert. Das opsi-check-plugin wird aufgerufen mit dem Befehl check_opsi. Eine Übersicht der möglichen Optionen erhält man mit dem Parameter -h oder --help.
Die folgenden Optionen sind für alle Checks notwendig:
Optionen |
Bezeichnung |
Beispiel |
-H,--host |
opsiServer auf dem gecheckt werden soll |
configserver.domain.local |
-P,--port |
opsi-Webservice Port |
4447 (Default) |
-u,--username |
opsi Monitoring User |
monitoring |
-p,--password |
opsi Monitoring Password |
monitoring123 |
-t,--task |
opsi Checkmethode (Case Sensitive) |
Die oben aufgeführten Parameter müssen immer gesetzt werden. Das nachfolgende Kapitel erläutert als erstes, wie man das opsi-check-plugin manuell aufrufen würde. Wie diese über Nagios/Icinga gesetzt werden, wird im Kapitel der Konfiguration erläutert.
Um das check-plugin vom opsi-Nagios-Connector zu installieren, können Sie einfach das opsi-Repository auf dem Nagios-Server eintragen und mit folgendem Befehl das Paket installieren:
apt-get install opsi-nagios-pluginsFür Redhat/Centos:
yum install opsi-nagios-pluginsFür OpenSuse/SLES:
zypper install opsi-nagios-pluginsDas Plugin selbst ist in Python geschrieben und sollte auch auf anderen Distributionen laufen. Dieses Paket basiert auf dem Paket: 'nagios-plugins-basic' bzw. 'nagios-plugins' und installiert entsprechend das Plugin ins Verzeichnis: /usr/lib/nagios/plugins. Die Konfiguration der Nagios-Check-Commands wird nicht automatisch angelegt, da dieses Plugin sehr flexibel einsetzbar ist. Deshalb wird dieser Teil im Kapitel über die Konfiguration etwas später näher erläutert.
Check: opsi-Webservice
Mit diesem Check wird der opsi-Webservice-Prozess überwacht. Dieser Check liefert auch Performancewerte. Deshalb sollte dieser Check auf jedem opsi-Server selbst ausgeführt werden, da jeder opsi-Server seinen eigenen opsiconfd-Prozess hat, der überwacht werden kann bzw. sollte.
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 -t checkOpsiWebserviceDieser Check liefert in der Regel OK zurück. In folgenden Situationen kann dies Abweichen:
-
Critical: Wenn der Webservice ein Problem hat und nicht richtig antwortet. Weiterhin wird dieser Status zurückgemeldet, wenn die CPU-Last des Prozesses 80% überschreitet oder wenn der prozentuale Wert von RPC-Errors 20% erreicht und übersteigt (im Bezug auf die gesamten RPCs).
-
Warning: Wenn der Webservice zwar arbeitet, aber Grenzwerte überschreitet: CPU Auslastung höher als 60% aber unter 80% oder wenn der prozentuale Wert der RPC-Errors in Bezug auf die Gesamt-RPC Anzahl höher als 10% aber unter 20% liegt.
-
Unknown: Wenn der Webservice gar nicht erreichbar ist.
Info: Die CPU-Werte beziehen sich immer nur auf eine CPU, da ein Prozess auch nur einen Prozessor benutzen kann. Eine Ausnahme bildet hier das Multiprocessing von opsi.
Check: opsi-check-diskusage
Mit diesem Check werden die opsiconfd-Ressourcen auf Füllstand überwacht. Die folgende Tabelle zeigt, welche Ressourcen damit gemeint sind.
Ressource |
Pfad |
/ |
/usr/share/opsiconfd/static |
configed |
/usr/lib/configed |
depot |
/var/lib/opsi/depot |
repository |
/var/lib/opsi/repository |
Bitte auch hier beachten, dass nur die Füllstände der Pfade, die für opsi relevant sind, beim Check berücksichtigt werden. Dieser Check soll keinen allgemeinen DiskUsage-Check ersetzen.
Mit folgendem Befehl kann man alle Ressourcen gleichzeitig abfragen:
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 -t checkOpsiDiskUsageZusätzlich zu der normalen Checkvariante gibt es die Möglichkeit, nur eine Ressource zu checken. Das folgende Beispiel checkt nur nach der Ressource repository:
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 -t checkOpsiDiskUsage --resource repositoryStandardmäßig gibt dieser Check OK zurück und gibt den freien Speicherplatz der Ressource oder der Ressourcen zurück. Die Einheit ist dabei Gigabyte. Folgende weitere Zustände sind möglich:
-
WARNING: Wenn eine oder mehrere Ressourcen 5GB oder weniger freien Speicherplatz haben.
-
CRITICAL: Wenn eine oder mehrere Ressourcen 1GB oder weniger freien Speicherplatz haben.
Die oben genannten Werte sind die Standard-Thresholds. Diese können durch zusätzliche Angabe von den Optionen -C und -W bzw. --critical und --warning selber bestimmt werden. Dabei gibt es zwei mögliche Einheiten: 10G bedeutet mindestens 10 Gigabyte freier Speicherplatz, durch diese Angabe wird der Output auch in dieser Datei ausgegeben. Wenn die Thresholds in Prozent oder ohne Angaben angegeben werden, wird auch der Output in Prozent generiert. Abschließend noch ein Beispiel zur Veranschaulichung:
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 -t checkOpsiDiskUsage --resource repository --warning 10% --critical 5%Check: opsi-client-status
Einer von zwei Schwerpunkten des opsi-Nagios-Connectors ist das Überwachen von Software-Rollouts. Dafür wurde dieser Check konzipiert. Er bezieht sich immer auf einen Client innerhalb von opsi.
Der Status der Produkte auf dem Client entscheidet über das Ergebnis des Checks. Auf diese Weise erkennt man schnell, ob eine Produktinstallation auf dem betreffenden Client ansteht oder aktuell ein Problem verursacht hat. Aber nicht nur der Produktstatus des Clients kann das Checkergebnis beeinflussen, sondern auch wann dieser Client sich das letzte mal am Service gemeldet hat. Wenn der Client länger als 30 Tage nicht am Service war, wird der Check mindestens ein Warning als Ergebnis zurückgeben. Dieser Zeitraum orientiert sich an der Abfolge der Microsoft Patchdays. Wenn ein Client länger als 30 Tagen von der Softwareverteilung abgeschottet ist, sollte man den Client checken. Auf diese Weise kann man auch Clients im System finden, die schon lange inaktiv sind, die man im normalen Betrieb schnell übersieht.
Die Ergebnisse der Tests werden von folgenden zwei Grundregeln bestimmt:
-
Der Software rollout Status ist:
-
'OK'
wenn die Software auf dem Client in der selben Produkt- und Paketversion installiert ist, welche auf dem Server liegt und kein 'Action Request' gesetzt ist. -
'Warning'
wenn die auf dem Client installierte Software von der Version auf dem Server abweicht oder ein 'Action Request' gesetzt ist. -
'Critical'
wenn die letzte Aktion für die Software auf dem Client ein 'failed' zurückgeliefert hat.
-
-
Die Zeit seit 'last seen' liefert:
-
'OK'
wenn der Client vor 30 Tagen oder weniger gesehen wurde. -
'Warning'
wenn der Client vor mehr als 30 Tagen zum letzten Mal gesehen wurde.
-
Dieser Check kann auf verschiedene Weisen durchgeführt werden; die einfachste Variante:
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 -t checkClientStatus -c opsiclient.domain.localMan kann einzelne Produkte anhand ihre ID von diesem Check ausschließen. Dies würde zum Beispiel so aussehen:
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 -t checkClientStatus -c opsiclient.domain.local -x firefoxDas obige Beispiel schließt das Produkt 'firefox' aus diesem Check aus, somit würde dieser Check auch ein OK liefern, selbst wenn das Produkt 'firefox' bei dem Client auf 'failed' steht.
Check: opsi-check-ProductStatus
Der zweite Schwerpunkt des opsi-Nagios-Connectors ist das Überwachen von Software-Rollouts. Mit die wichtigste Aufgabe in einem Software-Verteilungssystem. Sobald eine neue Software, egal ob Standard-Software oder eigene Software mit opsi verwaltet, verteilt und aktuell gehalten wird, muss man den Rollout-Status im Auge behalten.
Das Ergebnis dieses Checks wird durch die folgenden Grundregeln bestimmt:
Der Software Rollout Status ist:
-
'OK'
wenn die Software auf dem Client in der selben Produkt- und Paketversion installiert ist, welche auf dem Server liegt und kein 'Action Request' gesetzt ist. -
'Warning'
wenn die auf dem Client installierte Software von der Version auf dem Server abweicht oder ein 'Action Request' gesetzt ist. -
'Critical'
wenn die letzte Aktion für die Software auf dem Client ein 'failed' zurückgeliefert hat.
Durch einige Parameter kann man diesen Check flexibel einsetzen. Um dies besser zu verdeutlichen werden einige Beispielaufrufe aufgeführt und erläutert. Im einfachsten Fall ruft man den Check einfach für ein Produkt auf. Dieser wird als productId (opsi-interner Name) angegeben.
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 -t checkProductStatus -e firefoxIn einer normalen opsi-Umgebung reicht dieser Aufruf, um den Zustand für das Produkt firefox zu überwachen. Die Ausgabe zeigt an, ob alles in Ordnung ist oder wie viele Installationen anstehen (setup), wie viele Clients ein Problem mit diesem Produkt haben (failed) und wie viele Clients nicht die aktuelle Version installiert haben.
Dies ist zur Übersicht in den meisten Fällen schon ausreichend, wenn man aber nun genau wissen will, auf welchen Clients, welcher Zustand zu diesem Produkt zu diesem Checkergebnis geführt hat, kann man den Befehl im verbosemode ausführen:
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 -t checkProductStatus -e firefox -vBei einer Multi-Depot Umgebung wird der obige Befehl aber nicht die komplette Umgebung nach diesem Produkt überwachen, sondern nur den Configserver. (Oder exakter: Die Clients die dem depot auf dem config server zugewiesen sind). Wenn man mehrere Depotserver hat, kann man das Depot auch direkt mit angeben:
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 -t checkProductStatus -e firefox -d depotserver.domain.localDer Grund dafür ist, dass jeder Depotserver diese Produkt zur Verteilung haben kann. Dies muss nicht überall die selbe Version sein, auch wenn die productId genau die Selbe ist. Aus diesem Grund müssen alle Clients anders beurteilt werden, je nachdem an welchem Depot sie registriert sind. Dies hat zusätzlich noch den Vorteil, dass man diesen Check später im Nagios beim Depotserver ansiedeln kann, was zusätzlich die Übersichtlichkeit erhöht. Wenn man nur ein oder zwei Depotserver hat, kann man auch mit der Angabe von all alle Depotserver mit einem Check abdecken oder Komma separiert mehrere Depotserver angeben.
Zusätzlich kann man mit diesem Check auch mit opsi-Gruppen arbeiten. Man kann zum Beispiel eine ganze Produktgruppe mit einem Check abfragen. Wenn man zum Beispiel eine Produktgruppe: buchhaltung bildet, kann man mit folgendem Aufruf:
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 -t checkProductStatus -g buchhaltungNun werden alle Produkte, die Mitglieder in dieser Produktgruppe sind über diesen Check überwacht. Die Auswertung dieser Gruppe findet immer während des eigentlichen Checks statt; das bedeutet, man kann über opsi diese Gruppe bearbeiten und beeinflusst somit direkt die Check-Parameter ohne das man die Nagios-Konfiguration anpassen muss.
| Gruppen innerhalb von Gruppen werden nicht beachtet und müssen separat angegeben werden. |
Auch die Clients, die für diesen Check abgearbeitet werden, können beeinflusst werden. Wie vorher schon erwähnt, wird die Clientliste durch Angabe des Depotservers beeinflusst, zusätzlich können opsi-Hostgruppen angegeben werden, die für diesen Check abgearbeitet werden. Dieser Aufruf sieht zum Beispiel wie folgt aus:
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 -t checkProductStatus -g buchhaltung -G produktivclientsDies würde die Produkte der Produktgruppe 'buchhaltung' für alle Clients der Gruppe produktivclients überprüfen. Auch bei den Hostgruppen gilt die Regel, dass Untergruppen dieser Gruppe nicht abgearbeitet werden. Für opsi-Productgroups gilt genauso, wie für opsi-Hostgroups, dass mehrere Gruppen Komma separiert angegeben werden können.
Abschließend kann man auch bei diesem Check opsi-Clients ausschließen:
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 -t checkProductStatus -g buchhaltung -G produktivclients -x client.domain.localCheck: opsi-check-Depotsync
Gerade in einer Multi-Depot Umgebung ist es wichtig, die Depotserver auf Synchronität zu überwachen. Entscheidend ist bei diesem Check die Software- und Paketversion der installierten Produkte. Manchmal ist ein differenzierter Einsatz der opsi-Produkte auf Depotservern gewünscht, birgt aber die Gefahr, dass bei einem Umzug von einem Client, von einem Depot zum anderen, Inkonsistenzen in der Datenbank entstehen können. Um dieser Problematik entgegenzuwirken, wird empfohlen die opsi-Pakete auf den Depotservern so synchron wie möglich zu halten.
Standardmäßig liefert dieser Check 'OK' zurück, sollte eine Differenz festgestellt werden, wird der Status: 'WARNING' zurückgegeben. Dieser Check ist ein klassischer Check, der auf dem Configserver ausgeführt werden sollte, da alle Informationen zu diesem Check nur im Backend auf dem opsi-Configserver zu finden sind.
Als nächstes folgen ein paar Anwendungsmöglichkeiten dieses Checks:
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 -t checkOpsiDepotSyncStatusDies ist dies Basis-Variante und äquivalent zu folgendem Aufruf:
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 -t checkOpsiDepotSyncStatus -d allOhne konkrete Angabe von Depotserver werden die Produkt-Listen aller Depot-Server miteinander verglichen. Um eine bessere Übersichtlichkeit zu schaffen, sollte man diesen Check auf zwei Depotserver reduzieren und lieber auf mehrere Checks verteilen. Dies erreicht man durch direkte Angabe der Depotserver:
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 -t checkOpsiDepotSyncStatus -d configserver.domain.local,depotserver.domain.localMit diesem Aufruf werden alle Produkte verglichen, die auf beiden Depotservern installiert sind. Sollte ein Produkt auf einem Depotserver gar nicht installiert sein, hat dies keine Auswirkungen auf das Check-Resultat. Dies kann man ändern, indem man bei diesem Check den "strictmode" Schalter setzt:
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 -t checkOpsiDepotSyncStatus -d configserver.domain.local,depotserver.domain.local --strictmodeNun werden auch Produkte angezeigt, die auf einem Depotserver nicht installiert sind. Um ein bestimmtes Produkt oder bestimmte Produkte nicht mit zu checken, weil man zum Beispiel will, dass diese Produkte in verschiedenen Versionen eingesetzt werden, kann man diese Produkte von diesem Check ausschließen:
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 -t checkOpsiDepotSyncStatus -d configserver.domain.local,depotserver.domain.local --strictmode -x firefox,thunderbirdDieser Check würde auch dann ein OK zurückgeben, wenn das 'firefox' und das 'thunderbird'-Paket nicht überall synchron eingesetzt werden.
Ein weitere Einsatzmöglichkeit wäre, dass nur eine Auswahl von Produkten auf Synchronität überwacht werden können. Dies kann man durch:
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 -t checkOpsiDepotSyncStatus -d configserver.domain.local,depotserver.domain.local --strictmode -e firefox,thunderbirdSo werden nur 'firefox' und 'thunderbird' Produkte auf Synchronität überwacht. Bei diesem Check sollte der strictmode gesetzt sein, damit man auch erkennt, wenn die gewünschten Produkte auf Depotservern nicht installiert sind.
Check: Auf Depotservern gesperrte Produkte
Während der Installation eines neuen opsi-Paketes auf einem opsi-Server wird eine Sperre für das Produkt auf diesem Depot gesetzt. Sobald die Installation erfolgreich abgeschlossen wurde, wird die Sperre entfernt. Die Installation eines opsi-Paketes kann manchmal eine ungewöhnliche lange Zeit dauern, ohne dass ein Problem besteht. Falls die Sperre eine lange Zeit besteht, kann dies ein Indikator für Installationsprobleme sein.
Dieser Check sucht nach existierenden Sperren auf opsi-Servern.
Die Rückgabewerte sind:
* 'OK'
Falls keine Produkt-Sperren auf einem opsi-Server vorhanden sind.
* 'Warning'
Falls eine oder mehr Produkt-Sperren auf einem opsi-Server vorhanden sind.
Dieser Check sollte immer auf dem Config-Server ausgeführt werden, weil die benötigten Daten aus dem Backend des Config-Servers stammen.
Dieser Check benötigt mindestens die folgenden Versionen:
| Paket | Version |
|---|---|
opsi-nagios-plugins |
>=4.1.1.1 |
opsiconfd |
>=4.1.1.11 |
Einfacher Aufruf des Checks:
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 --task checkProductLocksDiese Variante ist gleichbedeutend mit dem folgenden Aufruf:
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 --task checkProductLocks --depotIds allFalls Sie die Prüfung auf bestimmte Depotserver einschränken wollen, müssen diese als kommaseparierte Liste angegeben werden. Das Ergebnis kann schwerer zu interpretieren sein, wenn die Ausgabe für mehrere Server gemischt wird, weshalb die Empfehlung ist, eine Prüfung pro Depot einzurichten.
Das folgende Beispiel prüft die beiden Depotserver 'configserver.domain.local' und 'depotserver.domain.local':
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 --task checkProductLocks --depotIds configserver.domain.local,depotserver.domain.localDer Standard ist, dass alle Produkte geprüft werden. Die Einschränkung auf bestimmte Produkte ist möglich. Es wird eine kommaseparierte Liste der Produkt IDs zum Filtern verwendet.
Das folgende Beispiel schränkt den vorherigen Check auf weiter ein und prüft nur die Produkte 'opsi-client-agent' und 'opsi-winst':
check_opsi -H configserver.domain.local -P 4447 -u monitoring -p monitoring123 --task checkProductLocks --depotIds configserver.domain.local,depotserver.domain.local --productIds opsi-client-agent,opsi-winstopsi Monitoring Konfiguration
Dieses Kapitel widmet sich der Konfiguration der Schnittstelle von opsi und dem Nagios-Server. Die Konfigurationen in diesem Kapitel, besonders die auf dem Nagios-Server, sollen als Empfehlungen gelten, sind aber nicht die einzigen Lösungen. Hier wird nur die Konfiguration mit einem Nagios-Server beschrieben. Mit einem Icinga-Server sollte, mit Ausnahme von ein paar Pfaden, die Konfiguration ziemlich genauso funktionieren. Andere Derivate auf Nagios Basis sollten funktionieren, wurden aber nicht getestet.
|
Die Konfigurationsdateien aus diesem Kapitel sind Bestandteil des opsi-nagios-connector-utils svn-Repository. Um die Beispiel-Konfigurationsdateien direkt zu beziehen, können Sie auf dieses Repository per Browser zugreifen: oder direkt per svn ein Checkout ausführen: |
opsi Monitoring User
In der Regel wird im Monitoring-Bereich viel mit IP-Freischaltungen als Sicherheit gearbeitet. Da aber dieser Mechanismus nicht wirklich einen Schutz bietet, wurde beim opsi-Nagios-Connector darauf verzichtet. Aus diesem Grund wird das Ganze per Benutzer und Passwort geschützt. Diesen User als opsi-admin einzurichten, würde aber auch hier zu viele Rechte freischalten, da dieser User nur für diese Schnittstelle von Nöten ist und auch die Benutzbarkeit auf diesen Bereich eingeschränkt werden soll, wird der User nur intern in opsi eingerichtet. Folgender Befehl legt den User an:
opsi-admin -d method user_setCredentials monitoring monitoring123Dieser Befehl legt den User: monitoring mit dem Passwort monitoring123 an. Der User wird in der /etc/opsi/passwd angelegt und ist auch kein User, mit dem man sich an der Shell anmelden könnte.
Bei einer Multi-Depot Umgebung muss man diesen User nur auf dem Configserver erzeugen.
Beim Nagios-Server kann man dieses Passwort vor den CGI-Skripten maskieren, indem man einen Eintrag in der /etc/nagios3/resource.cfg vornimmt. Dieser sieht zum Beispiel so aus:
$USER2$=monitoring
$USER3$=monitoring123Die Zahl hinter '$USER' kann variieren. Wenn diese Datei vorher nicht genutzt wurde, sollte in der Regel nur das $USER1$ belegt sein. Diese Konfiguration dient als Grundlage für die weiteren Konfigurationen.
opsi Nagios-Connector Konfigurationsverzeichnis
Aus Gründen der Übersichtlichkeit empfiehlt es sich für die Konfigurationsdateien des opsi-Nagios-Connectors ein eigenes Verzeichnis anzulegen.
Erzeugen Sie dazu unterhalb von: /etc/nagios3/conf.d ein Verzeichnis opsi. Dies macht die Konfiguration später übersichtlicher, da alle Konfigurationen, die den opsi-Nagios-Connector betreffen, gebündelt auf dem Server abgelegt sind.
Zu den Konfigurationsdateien in diesem Verzeichnis gehören:
-
Nagios Template:
opsitemplates.cfg -
Hostgroups:
opsihostgroups.cfg -
Server Hosts:
<full name of the server>.cfg -
Kommandos:
opsicheckcommands.cfg -
Kontakte:
opsicontacts.cfg -
Services:
opsiservices.cfg
Um die Übersichtlichkeit noch weiter zu erhöhen sollten Sie unterhalb von /etc/nagios3/conf.d/opsi noch ein Verzeichnis clients anlegen, dass im Weiteren dazu dient, die Konfigurationsdateien für die Clients aufzunehmen.
Nagios Template: opsitemplates.cfg
Es gibt diverse Templates für diverse Objekte im Nagios. Dies ist eine Standard-Nagios Funktionalität, die hier nicht näher beschrieben wird. Diese Funktionalität kann man sich für opsi zu nutze machen, um sich später bei der Konfiguration die Arbeit zu vereinfachen.
Da die meisten Checks auf dem Configserver ausgeführt werden, sollte man sich als erstes ein Template für die opsi-Server und ein Template für die opsi-Clients schreiben. Da es in einer Multi-Depot Umgebung nur einen Configserver geben kann, kann man direkt diesen ins Template übernehmen. Dies erreicht man am einfachsten über eine Custom-Variable. Diese erkennt man daran, dass sie mit einem _ beginnen. Es wird in das Template für den opsi-Server und die opsi-Clients folgendes zusätzlich eingetragen:
_configserver configserver.domain.local
_configserverurl 4447Auf diese beiden 'custom Variablen' kann man später einfach mit dem Nagios-Makro: $_HOSTCONFIGSERVER$ und $_HOSTCONFIGSERVERPORT$, verweisen. HOST muss vorher angegeben werden, da diese Custom-Variablen in einer Hostdefinition vorgenommen wurden. Weitere Informationen zu Custom-Variablen entnehmen Sie bitte der Nagios-Dokumentation. Da diese beiden Konfigurationen im Template vorgenommen werden müssen, gelten sie für jede Hostdefinition, die später von diesen Templates erben. Aber dazu später mehr.
Um nun die Templates anzulegen, sollte man unterhalb von: /etc/nagios3/conf.d als erstes ein Verzeichnis opsi erstellen. Dies macht die Konfiguration später übersichtlicher, da alle Konfigurationen, die den opsi-Nagios-Connector betreffen, gebündelt auf dem Server abgelegt sind. In diesem Verzeichnis erstellt man die Datei und benennt sie direkt so, dass man später erkennt, was genau hier konfiguriert werden soll: opsitemplates.cfg.
In dieser Datei können verschiedene Templates definiert werden. Die Templatedefinition richtet sich dabei nach folgendem Muster, bei dem zur besseren Verständlichkeit die Kommentare zu den einzelnen Einstellungen nicht gelöscht wurden:
define host{
name opsihost-tmp ; The name of this host template
notifications_enabled 1 ; Host notifications are enabled
event_handler_enabled 1 ; Host event handler is enabled
flap_detection_enabled 1 ; Flap detection is enabled
process_perf_data 0 ; Process performance data
retain_status_information 1 ; Retain status information across program restarts
retain_nonstatus_information 1 ; Retain non-status information across program restarts
max_check_attempts 10
notification_interval 0
notification_period 24x7
notification_options d,u,r
contact_groups admins
register 0 ; DONT REGISTER THIS DEFINITION - ITS NOT A REAL HOST, JUST A TEMPLATE!
icon_image opsi/opsi-client.png
}-
Optional kann durch die Option icon_image ein Image gesetzt werden, dieser muss relativ zum Pfad:
/usr/share/nagios3/htdocs/images/logos/angegeben werden. -
Optional kann auch eine eigene 'contact_group' angegeben werden, die allerdings als Contact-Object z.B. in der
opsicontacts.cfgangelegt sein muss.
Wir empfehlen Templates für folgende Objekte anzulegen:
-
opsi server
-
opsi client
-
opsi service
Zunächst das Beispiel des opsi-Server-Templates:
define host{
name opsi-server-tmpl
notifications_enabled 1
event_handler_enabled 1
flap_detection_enabled 1
process_perf_data 1
retain_status_information 1
retain_nonstatus_information 1
check_command check-host-alive
max_check_attempts 10
notification_interval 0
notification_period 24x7
notification_options d,u,r
contact_groups admins,opsiadmins
_configserver configserver.domain.local
_configserverport 4447
register 0
icon_image opsi/opsi-client.png
}Hier muss natürlich noch 'configserver.domain.local' an die lokalen Gegebenheiten angepasst werden. Auch die 'contact_groups' bedürfen evtl. der Anpassung.
Als nächster Teil der Datei opsitemplates.cfg das Template für die Clients:
define host{
name opsi-client-tmpl
notifications_enabled 1
event_handler_enabled 1
flap_detection_enabled 1
process_perf_data 1
retain_status_information 1
retain_nonstatus_information 1
max_check_attempts 10
notification_interval 0
notification_period 24x7
notification_options d,u,r
contact_groups admins,opsiadmins
_configserver configserver.domain.local
_configserverport 4447
register 0
icon_image opsi/opsi-client.png
}Da die Clients in der Regel nicht durchlaufen, sollte die Option: "check command check-host-alive" nicht gesetzt werden. Somit werden die Clients als Pending angezeigt und nicht als Offline.
Hier muss natürlich noch 'configserver.domain.local' an die lokalen Gegebenheiten angepasst werden. Auch die 'contact_groups' bedürfen evtl. der Anpassung.
Als nächster Teil der Datei opsitemplates.cfg das Template für die opsi-services:
define service{
name opsi-service-tmpl
active_checks_enabled 1
passive_checks_enabled 1
parallelize_check 1
obsess_over_service 1
check_freshness 0
notifications_enabled 1
event_handler_enabled 1
flap_detection_enabled 1
process_perf_data 1
retain_status_information 1
retain_nonstatus_information 1
notification_interval 0
is_volatile 0
check_period 24x7
check_interval 5
retry_interval 1
max_check_attempts 4
notification_period 24x7
notification_options w,u,c,r
contact_groups admins,opsiadmins
register 0
}opsi Hostgroup: opsihostgroups.cfg
Als nächstes sollten folgende Hostgruppen erstellt werden. Dies dient zum einen der besseren Übersicht auf der Weboberfläche und hilft beim Konfigurieren der Services. Dafür sollte eine Datei Namens opsihostgroups.cfg mit folgendem Inhalt erstellt werden:
define hostgroup {
hostgroup_name opsi-Clients
alias OPSI-Clients
}
define hostgroup {
hostgroup_name opsi-server
alias OPSI-Server
members configserver.domain.local, depotserver.domain.local
}opsi Server: <full name of the server>.cfg
Als nächstes sollten die opsi-Server konfiguriert werden. Dies kann jeweils in einer eigenen Datei wie zum Beispiel configserver.domain.local.cfg oder eine Datei mit allen opsi-Hosts wie opsihost.cfg erfolgen. Der Inhalt sollte für opsi-Server folgendermaßen aussehen:
define host{
use opsi-server-tmpl
host_name configserver.domain.local
hostgroups opsi-server
alias opsi Configserver
address configserver.domain.local
}
define host{
use opsi-server-tmpl
host_name depotserver.domain.local
hostgroups opsi-server
alias opsi Depotserver
address depotserver.domain.local
}Folgende Erläuterungen zu den Werten: * 'use' bezeichnet, welches Template benutzt wird. * 'hostgroups' gibt an, welcher Hostgruppe der Server angehört.
opsi Clients: clients/<full name of the client>.cfg
Die opsi-Clients sollten mindestens folgendermaßen definiert werden:
define host{
use opsi-client-tmpl
host_name client.domain.local
hostgroups opsi-Clients
alias opsi client
address client.domain.local
_depotid depotserver.domain.local
}Die Clientkonfiguration bedient sich einer Sonderfunktion von Nagios. Die Option _depotid
ist eine sogenannte benutzerdefinierte Variable, die als Makro $_HOSTDEPOTID$ benutzt werden kann. Die Verwendung ist optional und wird verwendet, wenn die Ausführung eines direkten Checks nicht vom config server, sondern vom hier definierten Depotserver aus startet.
Um die Erstellung von vielen Client Konfigurationsdateien zu vereinfachen, können diese auf dem opsi-Config-Server mit folgendem Skript erstellt werden.
#!/usr/bin/env python
from OPSI.Backend.BackendManager import *
template = '''
define host {
use opsi-client-tmpl
host_name %hostId%
hostgroups opsi-Clients
alias %hostId%
address %hostId%
}
'''
backend = BackendManager(
dispatchConfigFile = u'/etc/opsi/backendManager/dispatch.conf',
backendConfigDir = u'/etc/opsi/backends',
extensionConfigDir = u'/etc/opsi/backendManager/extend.d',
)
hosts = backend.host_getObjects(type="OpsiClient")
for host in hosts:
filename = "%s.cfg" % host.id
entry = template.replace("%hostId%",host.id)
f = open(filename, 'w')
f.write(entry)
f.close()opsi Check-Kommandos Konfiguration: opsicommands.cfg
Die oben beschriebenen Check-Kommandos müssen nun mit den bisherigen Kommandos konfiguriert werden. Dafür sollte eine Datei mit dem Namen opsicommands.cfg erstellt werden. Hier wird eine Bespielkonfiguration angegeben; je nach dem, welche Funktionen Sie auf welche Weise verwenden wollen, müssen Sie diese Einstellungen nach eigenem Ermessen modifizieren.
Als erstes wird der Aufbau anhand eines Beispiels erläutert:
define command{
command_name check_opsi_clientstatus
command_line $USER1$/check_opsi -H $_HOSTCONFIGSERVER$ -P $_HOSTCONFIGSERVERPORT$ -u $USER2$ -p $USER3$ -t checkClientStatus -c $HOSTADDRESS$
}Der command_name dient zur Referenzierung der weiteren Konfiguration. In der Option command_line werden die Konfigurationen und das Check-Kommando als erstes vereint.
Nach diesem Prinzip baut man nun die ganze Datei opsicommands.cfg auf:
define command {
command_name check_opsiwebservice
command_line /usr/lib/nagios/plugins/check_opsi -H $HOSTADDRESS$ -P 4447 -u $USER2$ -p $USER3$ -t checkOpsiWebservice
}
define command {
command_name check_opsidiskusage
command_line /usr/lib/nagios/plugins/check_opsi -H $HOSTADDRESS$ -P $_HOSTCONFIGSERVERPORT$ -u $USER2$ -p $USER3$ -t checkOpsiDiskUsage
}
define command {
command_name check_opsiclientstatus
command_line /usr/lib/nagios/plugins/check_opsi -H $_HOSTCONFIGSERVER$ -P $_HOSTCONFIGSERVERPORT$ -u $USER2$ -p $USER3$ -t checkClientStatus -c $HOSTADDRESS$
}
define command {
command_name check_opsiproductstatus
command_line /usr/lib/nagios/plugins/check_opsi -H $_HOSTCONFIGSERVER$ -P $_HOSTCONFIGSERVERPORT$ -u $USER2$ -p $USER3$ -t checkProductStatus -e $ARG1$ -d $HOSTADDRESS$ -v
}
define command {
command_name check_opsiproductStatus_withGroups
command_line /usr/lib/nagios/plugins/check_opsi -H $_HOSTCONFIGSERVER$ -P $_HOSTCONFIGSERVERPORT$ -u $USER2$ -p $USER3$ -t checkProductStatus -g $ARG1$ -G $ARG2$ -d "all"
}
define command {
command_name check_opsiproductStatus_withGroups_long
command_line /usr/lib/nagios/plugins/check_opsi -H $_HOSTCONFIGSERVER$ -P $_HOSTCONFIGSERVERPORT$ -u $USER2$ -p $USER3$ -t checkProductStatus -g $ARG1$ -G $ARG2$ -v -d "all"
}
define command {
command_name check_opsidepotsync
command_line /usr/lib/nagios/plugins/check_opsi -H $_HOSTCONFIGSERVER$ -P $_HOSTCONFIGSERVERPORT$ -u $USER2$ -p $USER3$ -t checkDepotSyncStatus -d $ARG1$
}
define command {
command_name check_opsidepotsync_long
command_line /usr/lib/nagios/plugins/check_opsi -H $_HOSTCONFIGSERVER$ -P $_HOSTCONFIGSERVERPORT$ -u $USER2$ -p $USER3$ -t checkDepotSyncStatus -d $ARG1$ -v
}
define command {
command_name check_opsidepotsync_strict
command_line /usr/lib/nagios/plugins/check_opsi -H $_HOSTCONFIGSERVER$ -P $_HOSTCONFIGSERVERPORT$ -u $USER2$ -p $USER3$ -t checkDepotSyncStatus -d $ARG1$ --strict
}
define command {
command_name check_opsidepotsync_strict_long
command_line /usr/lib/nagios/plugins/check_opsi -H $_HOSTCONFIGSERVER$ -P $_HOSTCONFIGSERVERPORT$ -u $USER2$ -p $USER3$ -t checkDepotSyncStatus -d $ARG1$ --strict -v
}Kontakte: opsicontacts.cfg
define contact{
contact_name adminuser
alias Opsi
service_notification_period 24x7
host_notification_period 24x7
service_notification_options w,u,c,r
host_notification_options d,r
service_notification_commands notify-service-by-email
host_notification_commands notify-host-by-email
email root@localhost
}
define contactgroup{
contactgroup_name opsiadmins
alias opsi Administrators
members adminuser
}Hier müssen Sie natürlich 'adminuser' in einen bzw. mehrere reale User abändern.
Services: opsiservices.cfg
In der Konfiguration der 'Services' wird nun endlich angegeben, was der Nagios-Server monitoren und anzeigen soll. Dabei wird nun auf die bisher definierten Templates, commands und hostgroups bzw. hosts zugegriffen.
Zunächst der Teil der Services, die die tatsächlichen Zustände der Server betreffen. Hierbei wird beim Check auf den Depotsync gegen alle bekannten Services ('all') geprüft.
#OPSI-Services
define service{
use opsi-service-tmpl
hostgroup_name opsi-server
service_description opsi-webservice
check_command check_opsiwebservice
check_interval 1
}
define service{
use opsi-service-tmpl
hostgroup_name opsi-server
service_description opsi-diskusage
check_command check_opsidiskusage
check_interval 1
}
define service{
use opsi-service-tmpl
hostgroup_name opsi-server
service_description opsi-depotsyncstatus-longoutput
check_command check_opsidepotsync_long!all
check_interval 10
}
define service{
use opsi-service-tmpl
hostgroup_name opsi-server
service_description opsi-depotsyncstatus-strict-longoutput
check_command check_opsidepotsync_strict_long!all
check_interval 10
}Nun der Teil der das Softwarerollout überwacht. Dabei wird in einem Check auf das opsi-Produkt 'opsi-client-agent' verwiesen und zwei andere Checks verwenden hier eine opsi-Produktgruppe 'opsiessentials' sowie eine opsi-Clientgruppe 'productiveclients'.
define service{
use opsi-service-tmpl
hostgroup_name opsi-Clients
service_description opsi-clientstatus
check_command check_opsiclientstatus
check_interval 10
}
define service{
use opsi-service-tmpl
hostgroup_name opsi-server
service_description opsi-productstatus-opsiclientagent
check_command check_opsiproductstatus!opsi-client-agent
check_interval 10
}
define service{
use opsi-service-tmpl
hostgroup_name opsi-server
service_description opsi-productstatus-opsiessentials-group
check_command check_opsiproductStatus_withGroups!opsiessentials!productiveclients
check_interval 10
}
define service{
use opsi-service-tmpl
hostgroup_name opsi-server
service_description opsi-productstatus-opsiessentials-group-longoutput
check_command check_opsiproductStatus_withGroups_long!opsiessentials!productiveclients
check_interval 10
}